 scrapy
scrapy
Scrapy 是一个用于构建和管理网络爬虫的强大 Python 框架。它提供了许多工具和功能, 使你能够轻松地抓取网页上的数据, 处理和存储数据。以下是一些关于 Scrapy 库的主要特点和功能:
灵活性和可扩展性: Scrapy 提供了一个灵活的框架, 允许你定义自己的爬虫规则和数据流程。你可以编写自定义爬虫, 处理不同网站的结构和数据异步请求: Scrapy 支持异步请求, 允许你同时处理多个请求, 提高了爬取效率选择器: Scrapy 内置了 XPath 和 CSS 选择器, 用于从网页中提取数据。这使得数据抽取变得相对容易中间件: Scrapy 允许你添加自定义中间件, 以执行各种操作, 如代理、用户代理伪装、请求和响应的处理等数据流管道: Scrapy 允许你定义数据处理管道, 以将抓取到的数据保存到不同的数据存储, 如数据库、JSON 文件、CSV 文件等自动限速: Scrapy 具有内置的请求限速功能, 以避免对目标网站的过度访问扩展性: Scrapy 的架构非常灵活, 允许你编写扩展或插件, 以添加自定义功能用户文档和社区支持: Scrapy 拥有丰富的用户文档和一个活跃的社区, 可以提供支持和解决问题内置的调试工具: Scrapy 提供了一些内置工具, 用于调试和分析爬取过程定时任务: 你可以使用 Scrapy 来创建定时任务, 以定期抓取网站上的数据
Scrapy 是一个强大的爬虫框架, 适用于各种网络爬虫任务, 包括数据挖掘、数据收集、搜索引擎爬虫等。如果你需要构建一个高效且可扩展的网络爬虫应用, Scrapy 是一个值得考虑的工具。通过学习 Scrapy, 你可以更轻松地抓取和处理互联网上的数据
# scrapy 工作流程
下方参考文章, scrapy 爬虫框架——概念作用和工作流程 & scrapy 的入门使用 (opens new window)
# workflow
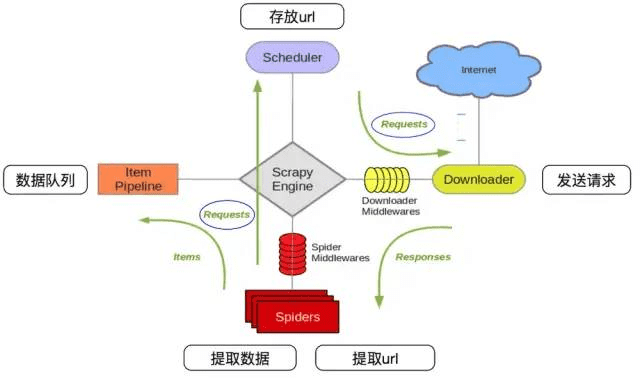
其流程可以描述如下:
- 爬虫中起始的 url 构造成 request 对象–>爬虫中间件–>引擎–>调度器
- 调度器把 request–>引擎–>下载中间件—>下载器
- 下载器发送请求, 获取 response 响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取 url 地址, 组装成 request 对象---->爬虫中间件—>引擎—>调度器, 重复步骤 2
- 爬虫提取数据—>引擎—>管道处理和保存数据
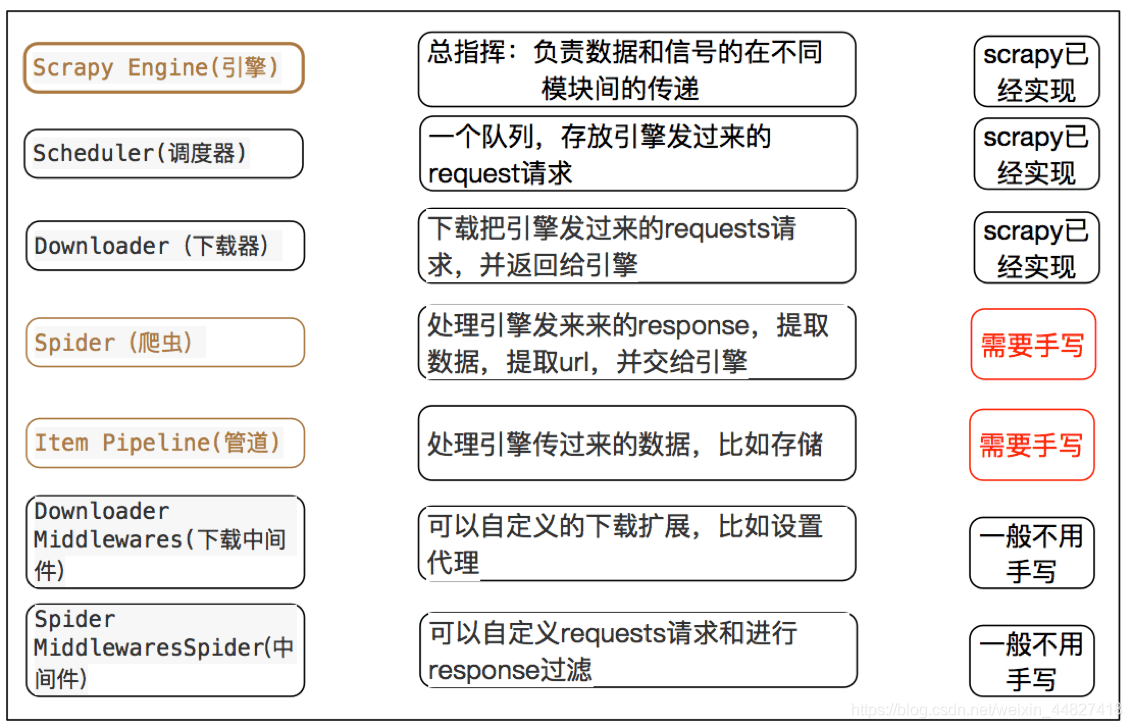
# 每个模块的具体作用
# command (opens new window)
scrapy startproject <tutorial>: create a tutorial projectscrapy crawl <quotes>: This command runs the spider with name quotes- scrapy shell
# help
Scrapy 2.11.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# api
Crawler API:
- CrawlerProcess: CrawlerProcess 是 Scrapy 的高级 API, 用于配置和启动多个爬虫同时运行
- Crawler: Crawler 是一个具体的爬虫实例, 它负责处理一个网站的抓取任务
Spider API:
- scrapy.Spider: Spider 是一个 Scrapy 爬虫的基类, 开发者可以从这个基类继承并自定义爬虫
- name: 用于标识爬虫的名称
- start_urls: 包含爬虫起始 URL 的列表
- parse(): 用户自定义的解析方法, 用于处理从网页提取的数据
Request and Response API:
- scrapy.Request: 用于创建 HTTP 请求的类, 包括 URL、回调函数等
- scrapy.Response: 包含 HTTP 响应数据的类, 通常由爬虫的回调函数处理
Item API:
- scrapy.Item: Item 是用于封装抓取到的数据的容器, 通常定义为 Python 类, 每个字段都由 Item 的属性表示
Selector API:
- scrapy.Selector: Selector 是用于从 HTML 或 XML 文档中提取数据的工具, 提供了 XPath 和 CSS 选择器的支持
Middleware API:
- 中间件(Middleware)是 Scrapy 中用于处理请求和响应的组件, 允许开发者进行自定义处理, 如 User-Agent 设置、代理、重定向等
Downloader API:
- scrapy.downloadermiddlewares: 提供了一系列内置的下载器中间件, 用于处理 HTTP 请求和响应的下载过程
Pipeline API:
- scrapy.Pipeline: Pipeline 是用于处理抓取到的数据的组件, 允许开发者定义多个数据处理步骤, 如数据清洗、存储、导出等
Settings API:
- scrapy.settings: 用于管理 Scrapy 爬虫的设置和配置
Command-line Interface (CLI):
- Scrapy 提供了命令行工具, 允许你创建、运行和管理爬虫
这些是 Scrapy 中的一些主要 API 和组件, 它们允许开发者构建高效的网络爬虫, 从目标网站中提取数据。Scrapy 还提供了广泛的文档和教程, 帮助开发者学习如何使用这些 API 来构建和管理爬虫。通过这些 API, 你可以定制各种功能和操作, 以满足不同的抓取需求
# selector
Querying responses using XPath and CSS is so common that responses include two more shortcuts: response.xpath() and response.css()。 For reading more, click me
# API
attrib: SelectorList, it returns attributes for the first matching element
response.css("img::text").get(default=""): with default valueresponse.xpath("//title/text()").get()response.css("title::text").get()response.xpath("//img/@src").get()response.css("img").xpath("@src").getall()response.css("img::attr(src)").getall()response.css("base").attrib["href"]: 此方案只能获取到第一个匹配的元素response.xpath('//div[@id="images"]/a/text()').get()response.xpath('//div[@id="images"]/a/text()').get(default='not found')- CSS
title::text: selects children text nodes of a descendant<title>element*::text: selects all descendant text nodes of the current selector context#images *::text: 选择 id 属性为 images 的元素的所有子元素的文本内容
[href*=image]::attr(href): 使用属性选择器, 筛选具有 href 属性包含 "image" 的元素, 获取 href 属性值[href*=image] img::attr(src): 1. 选择 href 包含 image 的元素 2.所有子元素img的 src 属性内容[href^='https']: 选择具有以 "https" 开头的 href 属性的元素
- 复合选择
response.css("div[class=yizhu] img[src*='bei-pic.png']::attr(onclick)").getall():response.css()是 Scrapy 框架中用于执行 CSS 选择器的方法, 它会返回一个 SelectorList 对象, 其中包含了匹配到的元素div[class=yizhu] img[src*='bei-pic.png']是 CSS 选择器, 用于选取 class 属性为 "yizhu" 的 div 元素中, 包含 src 属性值包含 "bei-pic.png" 的 img 元素::attr(onclick)是 CSS 伪元素语法, 用于选取 img 元素的 onclick 属性getall()是 SelectorList 对象的方法, 用于获取所有匹配到的元素的属性值, 并以列表的形式返回
# css
[]: 指定条件::text: select text nodes::attr(name): select attribute values
Nesting selectors
response.xpath('//a[contains(@href, "image")]/@href'): 用 contains 函数来筛选具有 href 属性包含 "image" 的元素
The selection methods (.xpath() or .css()) return a list of selectors of the same type, so you can call the selection methods for those selectors too.
>>> links = response.xpath('//a[contains(@href, "image")]')
>>> links.getall()
['<a href="image1.html">Name: My image 1 <br><img src="image1_thumb.jpg" alt="image1"></a>',
'<a href="image2.html">Name: My image 2 <br><img src="image2_thumb.jpg" alt="image2"></a>',
'<a href="image3.html">Name: My image 3 <br><img src="image3_thumb.jpg" alt="image3"></a>',
'<a href="image4.html">Name: My image 4 <br><img src="image4_thumb.jpg" alt="image4"></a>',
'<a href="image5.html">Name: My image 5 <br><img src="image5_thumb.jpg" alt="image5"></a>']
>>> for index, link in enumerate(links):
href_xpath = link.xpath("@href").get()
img_xpath = link.xpath("img/@src").get()
print(f"Link number {index} points to url {href_xpath!r} and image {img_xpath!r}")
2
3
4
5
6
7
8
9
10
11
12
13
# xpath
# 其他
# shub
pip3 install shub
shub is the Scrapinghub(云端爬虫托管平台, 用于运行、调度和管理爬虫) command-line client. It allows you to deploy projects or dependencies, schedule spiders, and retrieve scraped data or logs without leaving the command line.
以下是一些常见的用途和操作, 你可以使用 shub 来完成:
部署项目: 你可以使用 shub 来将你的 Scrapy 项目部署到 Scrapinghub 平台, 以便在云端环境中运行和管理你的爬虫
调度爬虫: 通过 shub, 你可以在 Scrapinghub 平台上调度爬虫的运行, 定义运行时间和频率
检索抓取的数据: shub 允许你从 Scrapinghub 平台上检索已抓取的数据, 以便进一步处理或导出
查看日志: 你可以使用 shub 来查看和分析爬虫运行时生成的日志, 以便进行故障排除和性能优化
管理依赖: shub 还允许你管理 Scrapinghub 项目的依赖, 例如使用第三方 Python 包
总之, shub 是 Scrapinghub 平台的命令行接口, 使你能够直接从命令行中管理和操作云端爬虫项目, 而无需离开终端界面。这对于 Scrapy 项目的部署和运维非常有用, 尤其是当你需要在云端环境中扩展和管理大规模的爬虫任务时
# Items
https://docs.scrapy.org/en/latest/topics/items.html (opens new window)
示例
import scrapy
from MtimeSpider.items import MtimespiderItem
class MovieSpiderSpider(scrapy.Spider):
# ...
def parse(self, response):
# 各种解析...
movie_list = response.xpath('//ul[@id="asyncRatingRegion"]/li')
for movie_li in movie_list:
item = MtimespiderItem()
item['url'] = movie_li.xpath('div[@class="mov_pic"]/a/@href').extract_first()
# ...
yield item
# next request...
yield scrapy.Request(new_link, callback=self.parse)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
yield item的作用
在这个 Scrapy 爬虫中, yield item 的作用是将抓取到的电影信息封装成一个 MtimespiderItem 对象, 并将这个对象返回, 以供 Scrapy 框架进一步处理。具体作用如下:
抓取数据: 在 parse 方法中, 通过 XPath 表达式从网页中抓取电影信息, 包括电影的 URL、图片 URL、标题、导演、演员、简介、得分等信息
创建数据项: 为了将抓取到的数据组织成结构化的形式, 创建了一个 MtimespiderItem 对象, 将抓取到的信息赋值给这个对象的属性
返回数据项: 使用
yield item语句将 MtimespiderItem 对象返回给 Scrapy 框架。这实际上是将数据项放入 Scrapy 的管道(Pipeline)中, 以便进一步处理继续爬取: 在 parse 方法中, 还会继续请求下一页的链接(如果有), 并继续抓取更多电影信息。这是通过再次调用
yield scrapy.Request(new_link, callback=self.parse)来实现的
yield item 允许 Scrapy 异步处理抓取的数据项, 例如将数据保存到数据库、文件或进行其他处理。这种异步处理使得 Scrapy 非常高效, 因为它可以并行处理多个请求和数据项, 而不必等待每个请求的完成。这也是 Scrapy 框架的一个强大特性, 使得爬虫编写变得相对简单而高效
# settings.py 配置项
示例
# Scrapy settings for first_scrapy_project project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "first_scrapy_project"
SPIDER_MODULES = ["first_scrapy_project.spiders"]
NEWSPIDER_MODULE = "first_scrapy_project.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "first_scrapy_project (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "first_scrapy_project.middlewares.FirstScrapyProjectSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "first_scrapy_project.middlewares.FirstScrapyProjectDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# "first_scrapy_project.pipelines.FirstScrapyProjectPipeline": 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
BOT_NAME: 这是爬虫项目的名称, 用于标识项目SPIDER_MODULES和NEWSPIDER_MODULE: 这些设置用于指定爬虫模块的位置。SPIDER_MODULES指定了包含爬虫的模块, 而NEWSPIDER_MODULE指定了新爬虫的默认模块ROBOTSTXT_OBEY: 这个设置控制爬虫是否遵守网站的robots.txt文件中定义的规则, 以确保不爬取被禁止的内容CONCURRENT_REQUESTS: 这个设置指定了同时进行的最大请求数量DOWNLOAD_DELAY: 用于设置请求之间的下载延迟, 以防止对服务器造成过大的负担COOKIES_ENABLED: 控制是否启用 cookies, 用于模拟用户会话TELNETCONSOLE_ENABLED: 控制是否启用 Telnet 控制台, 通常用于远程调试DEFAULT_REQUEST_HEADERS: 可以用于设置默认的 HTTP 请求头, 例如 Accept 和 Accept-LanguageSPIDER_MIDDLEWARES和DOWNLOADER_MIDDLEWARES: 这些设置允许启用或禁用爬虫和下载器中间件, 用于自定义请求和响应处理逻辑ITEM_PIPELINES: 可以配置数据处理管道, 用于对爬取的数据进行处理和存储AUTOTHROTTLE_ENABLED: 启用或禁用自动节流扩展, 以限制爬虫的请求速率HTTPCACHE_ENABLED: 启用或禁用 HTTP 缓存, 用于缓存已下载的响应其他设置项可以用于配置一些扩展和特定功能, 如 Telnet 控制台、自动节流、HTTP 缓存等
这个配置文件包含了各种设置, 可以根据具体的爬虫项目需求进行自定义配置, 以满足不同的爬取任务
# 数据处理管道 (opens new window)
ItemAdapter: 一个方便的工具, 用于处理数据项(Item)DropItem: 用于在处理数据时可能抛出的异常情况process_item(self, item, spider): 数据处理管道的核心方法, 用于处理每个爬取到的数据项。它接收两个参数,item表示当前处理的数据项,spider表示当前的爬虫def open_spider(self, spider): 这是一个特殊的方法, 用于在爬虫开始运行时执行初始化操作def close_spider(self, spider): 这是一个特殊的方法, 用于在爬虫结束时执行清理操作
# debug scrapy script
https://docs.scrapy.org/en/latest/topics/debug.html (opens new window)
运行如下 python 脚本即可。 参考链接 (opens new window)
from scrapy import cmdline
cmdline.execute("scrapy runspider gushiwen/spiders/gushi.py".split())
2
3
# response 不全的问题
HTTP 头信息问题: 有些网站可能在 HTTP 头部信息中指定了响应内容的编码或压缩方式, Scrapy 默认会尝试根据头部信息来处理响应内容。如果服务器返回的头部信息与实际内容不匹配, 可能会导致内容不完整
网站动态加载: 如果网站使用 JavaScript 或 Ajax 请求来加载数据, Scrapy 可能只能获取到页面的初始 HTML, 而无法获取 JavaScript 动态生成的内容。您可能需要使用 Scrapy Splash(可执行的浏览器渲染引擎) 或 Selenium(自动化浏览器的工具) 等工具来处理动态加载的内容
响应被截断: 有些网站可能会对爬虫进行检测, 并主动中断响应, 导致您无法获取完整的内容。这通常需要使用反爬虫技术来解决
反爬虫机制: 网站可能使用反爬虫技术来检测和阻止爬虫程序, 这可能会导致响应内容不完整或无法访问
Scrapy 设置问题: 某些 Scrapy 设置可能会影响响应内容的获取。您可以检查 Scrapy 的设置, 如是否启用了下载中间件、并发请求数、下载延迟等
为了解决响应内容不完整的问题, 您可以采取以下步骤:
- 确保您的 Scrapy 项目设置正确, 包括适当的下载中间件和延迟设置
- 使用 Scrapy Splash 或 Selenium 等工具来处理动态加载的内容
- 了解目标网站的反爬虫机制, 以采取适当的对策
如果仍然存在问题, 您可能需要详细分析目标网站的结构和行为, 以找出问题的具体原因, 并调整爬虫的配置和代码来解决问题
# splash 与 scrapy
scrapy 和 splash 配合使用的过程中, splash 充当什么角色
在 Scrapy 和 Splash 配合使用的过程中, Splash 充当了一个渲染服务的角色, 用于处理动态加载的页面和 JavaScript 渲染。具体来说, Splash 用于执行 JavaScript 代码、渲染网页并返回渲染后的结果给 Scrapy, 以便 Scrapy 可以进一步分析和提取数据
以下是 Splash 在 Scrapy 中的作用:
JavaScript 渲染: 许多现代网站使用 JavaScript 来动态加载内容, 这使得传统的静态爬取方法无法获取完整的页面数据。Splash 允许 Scrapy 发送带有 JavaScript 代码的请求, 然后渲染和执行页面上的 JavaScript, 从而获取动态生成的内容
处理 AJAX 请求: Splash 可以模拟用户与页面的交互, 包括单击按钮、填写表单等, 以便触发页面上的 AJAX 请求。这使得 Scrapy 可以捕获通过 AJAX 加载的数据
渲染页面截图: Splash 可以渲染页面并生成截图, 这对于调试和可视化分析非常有用
等待元素加载: Splash 允许你设置等待条件, 以确保在提取数据之前等待特定元素或事件的加载。这对于处理页面加载延迟非常有用
用户代理设置: Splash 支持设置用户代理, 以模拟不同类型的浏览器和设备
Cookie 管理: 你可以在 Splash 中设置和管理 Cookies, 以模拟登录状态或维护会话
Splash 的主要优势是能够处理动态页面, 使 Scrapy 能够访问和提取那些传统爬虫无法轻松处理的内容。它允许 Scrapy 与 JavaScript 交互, 捕获由 JavaScript 生成的数据, 从而提供了更全面的网络爬虫解决方案。当你需要爬取 JavaScript 渲染的页面时, Splash 是一个强大的工具