 thread
thread
# state
https://juejin.im/post/5b31b510e51d4558a426f7e9 (opens new window)
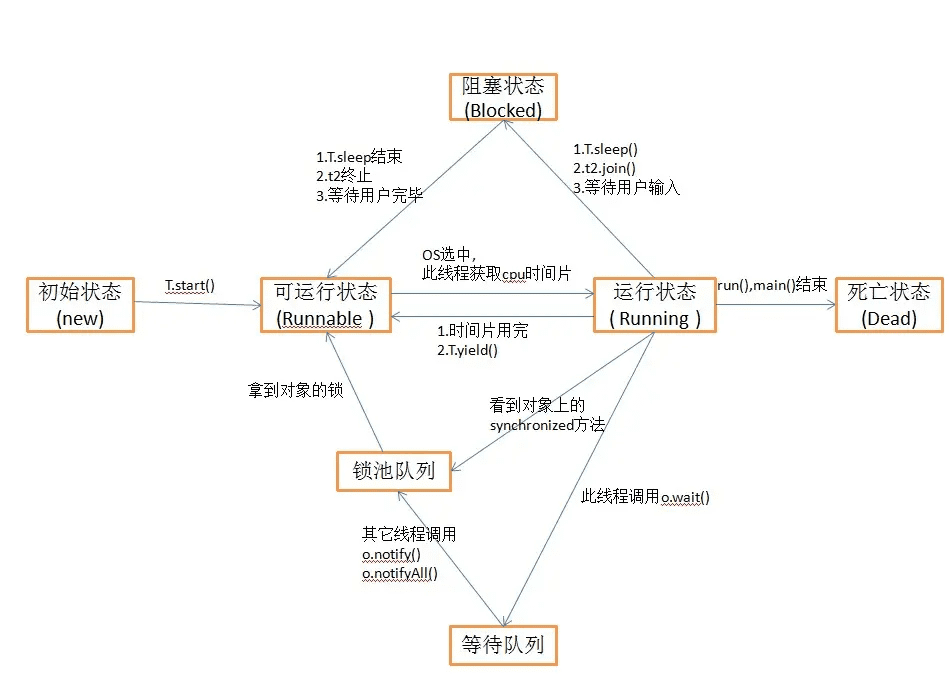
- 新状态: 线程对象已经创建, 还没有在其上调用
start()方法 - 就绪: 当线程有资格运行, 但调度程序还没有把它选定为运行线程, 这时候线程所处的状态就做就绪状态。当 start()方法调用时, 线程首先进入可运行状态。在线程运行之后或者从阻塞、等待或睡眠状态回来后, 也返回到可运行状态。另外 yield 可以让线程由"运行状态"进入到"就绪状态"
- 运行: 线程调度程序从可运行池中选择一个线程来执行。这也是线程进入运行状态的唯一一种方式
- 等待/阻塞/睡眠: 这是线程有资格运行时它所处的状态。实际上这个三状态组合为一种, 其共同点是: 线程仍旧是活的, 但是当前没有条件运行。换句话说, 它是可运行的, 但是如果某件事件出现, 他可能返回到可运行状态。另外 wait 可以让线程由"运行状态"进入到"等待(阻塞)状态"
- 死亡态: 当线程的 run()方法完成时就认为它死去。这个线程对象也许是活的, 但是, 它已经不是一个单独执行的线程。线程一旦死亡, 就不能复生。 如果在一个死去的线程上调用 start()方法, 会抛出 java.lang.IllegalThreadStateException 异常
# jvm 内存模型
Java 内存模型(Java Memory Model, JMM)是 Java 语言中关于线程如何通过内存进行交互的一套规范。JMM 规定了 Java 程序中变量的读写规则、可见性、原子性和有序性等,并定义了多线程环境下的内存访问行为。它确保了在并发情况下,程序能保持一致性和线程安全性
# JMM 的关键概念
- 主内存与工作内存
- 主内存(Main Memory): 所有线程共享的内存区域。Java 中的所有实例变量(对象字段)和静态变量都存储在主内存中
- 工作内存(Working Memory): 每个线程都有自己的工作内存,工作内存是线程私有的。线程只能直接访问自己的工作内存。工作内存中的变量是从主内存中拷贝过来的副本。线程对变量的修改首先发生在工作内存中,之后再同步回主内存
- 可见性
由于线程对变量的读取和写入操作通常是在各自的工作内存中进行的,因此一个线程对变量的更新不一定马上对其他线程可见。JMM 通过 volatile 关键字和锁机制来保证变量的可见性:
- volatile 变量: 对 volatile 变量的修改会直接写入主内存,读操作也会从主内存中读取,因此 volatile 变量可以保证对其他线程是可见的
- 同步机制(synchronized、Lock): 加锁和解锁操作会使线程之间的变量修改可见,因为这些操作会刷新工作内存和主内存之间的内容
- 原子性
原子性是指一个操作不会被线程调度机制打断,保证操作的完整性。JMM 规定了以下操作具有原子性:
- 基本类型的读取和写入(long 和 double 除外,除非使用 volatile)
- 对 volatile 变量的读取和写入
对于复合操作(如 i++),它并不具备原子性,需要通过锁或 AtomicInteger 等类来保证原子性
- 有序性
Java 语言规范允许编译器和处理器对代码进行重排序,以优化性能。虽然重排序在单线程中是无害的,但在多线程环境下可能会导致意外行为。JMM 提供了两种方式来保证线程之间的操作有序性:
- volatile 关键字: 保证 volatile 变量的读写操作不会被重排序
- 同步块(synchronized): 在同步块内的操作不会被重排序
- Happens-Before 规则
Happens-Before 是 JMM 用来规定操作执行顺序的规则。简单地说,Happens-Before 关系确保了一个操作的结果对另一个操作是可见的。JMM 定义了一些常见的 Happens-Before 关系:
- 线程中的每个操作都 Happens-Before 该线程中的任何后续操作
- 对一个对象的初始化 Happens-Before 该对象的引用可以被其他线程看到
- 对 volatile 变量的写入 Happens-Before 该变量的读取
- 一个线程的 unlock 操作 Happens-Before 另一个线程的 lock 操作
# JMM 中的常见问题
- 可见性问题 由于线程的操作都是在自己的工作内存中进行的,因此线程间可能无法立即看到彼此对变量的修改,导致共享变量的可见性问题。例如,一个线程更新了某个变量的值,另一个线程可能继续看到变量的旧值
解决办法: 使用 volatile 关键字或同步机制来确保变量的可见性
- 指令重排序 在编译器和处理器的优化下,代码可能会发生指令重排序。例如,某些代码语句在内存中的执行顺序可能不同于源码中的顺序。虽然单线程程序中这种优化是安全的,但多线程环境下可能会导致一些不符合预期的行为
解决办法: 使用 volatile 或 synchronized 来禁止重排序
- 原子性问题 一些非原子操作(如 i++)在多线程环境下可能会导致数据竞争,线程执行时会相互干扰,导致最终的结果不正确
解决办法: 使用 synchronized 或 Java 并发包中的 Atomic 类来保证原子性
# JMM 与 volatile 关键字
- volatile 的作用: volatile 修饰的变量具有以下两大特性:
- 可见性: 一个线程对 volatile 变量的写入对其他线程是立即可见的
- 禁止重排序: 对 volatile 变量的读写操作不会与其他内存操作重排序
但是,volatile 不能保证复合操作的原子性。因此,如果需要对 volatile 变量进行复合操作(如 i++),仍然需要额外的同步机制
# JMM 与 synchronized
synchronized 的作用: synchronized 可以确保两个线程对同步代码块的互斥访问,并且通过锁的释放和获取保证了可见性和有序性。即:
- 一个线程释放锁时,它对共享变量的修改会立即对其他获取同一锁的线程可见
- 进入同步代码块的所有线程都可以看到之前所有对锁的修改操作
Java 内存模型定义了 Java 程序在并发执行时内存操作的行为,解决了多线程环境下的可见性、原子性和有序性问题。通过 volatile、synchronized 以及 Atomic 类等机制,JMM 保证了线程之间共享数据的一致性,从而使得并发程序能够正确、安全地运行
# common method
# interrupt
Java 并发编程 之二: 线程中断 (opens new window)
注意一下: 待决中断
通常, 我们通过"标记"方式终止处于"运行状态"的线程。其中, 包括"中断标记"和"额外添加标记"
说明: isInterrupted()是判断线程的中断标记是不是为 true。当线程处于运行状态, 并且我们需要终止它时;可以调用线程的 interrupt()方法, 使用线程的中断标记为 true, 即 isInterrupted()会返回 true。此时, 就会退出 while 循环
注意: interrupt() 并不会终止处于"运行状态"的线程!它会将线程的中断标记设为 true
@Override
public void run() {
try {
// 1. isInterrupted()保证, 只要中断标记为true就终止线程
while (!isInterrupted()) {
// 执行任务...
}
} catch (InterruptedException ie) {
// 2. InterruptedException异常保证, 当InterruptedException异常产生时, 线程被终止
}
}
2
3
4
5
6
7
8
9
10
11
# wait
* The current thread must own this object's monitor. The thread
* releases ownership of this monitor and waits until another thread
* notifies threads waiting on this object's monitor to wake up
* either through a call to the {@code notify} method or the
* {@code notifyAll} method. The thread then waits until it can
* re-obtain ownership of the monitor and resumes execution.
2
3
4
5
6
wait() 的作用是让当前线程进入等待状态, 同时,让当前线程释放它所持有 object 对象锁
# notify/notifyAll
Wakes up all threads that are waiting on this object's monitor. A thread waits on an object's monitor by calling one of the {@code wait} methods. This method should only be called by a thread that is the owner of this object's monitor.
- 唤醒此对象监视器上所有的等待的线程。一旦一个对象调用了 wait 方法, 必须要采用 notify()和 notifyAll()方法唤醒该线程
- notify()和 notifyAll()的作用, 则是唤醒在此对象监视器上等待的单个/全部线程
# join (opens new window)
join() 方法的作用, 是等待这个线程结束;
t.join() 方法阻塞调用此方法的线程(calling thread), 直到线程 t 完成, 此线程再继续;通常用于在 main()主线程内, 等待其它线程完成再结束 main()主线程
源码中:
Join 方法实现是通过 wait(小提示: Object 提供的方法)。 当 main 线程调用 t.join 时候, main 线程会获得线程对象 t 的锁(wait 意味着拿到该对象的锁),调用该对象的 wait(等待时间), 直到该对象唤醒 main 线程 , 比如退出后。这就意味着 main 线程调用 t.join 时, 必须能够拿到线程 t 对象的锁
# wait 和 yield(或 sleep)的区别?
wait()是让线程由"运行状态"进入到"等待(阻塞)状态" yield()是让线程由"运行状态"进入到"就绪状态", 从而让其它具有相同优先级的等待线程有机会获取执行权;但是, 并不能保证在当前线程调用 yield()之后, 其它具有相同优先级的线程就一定能获得执行权。 > wait()是会在线程释放它所持有对象的同步锁, 而 yield()方法不会释放锁。 Thread.sleep(long millis)和 Thread.sleep(long millis, int nanos)静态方法强制当前正在执行的线程休眠.当线程睡眠时, 它入睡在某个地方, 在苏醒之前不会返回到可运行状态。当睡眠时间到期, 则返回到可运行状态(就绪)
# 线程死锁, 如何避免线程死锁?
- 什么是死锁: 多个线程因竞争资源而造成的一种僵局(互相等待), 若无外力作用, 这些进程都将无法向前推进
# 同步/异步
# 1.Object 的 wait 和 notify/notifyAll/synchronized 如何实现线程同步?
以 android 中的 HandlerThread (Handy class for starting a new thread that has a looper) 的源码为例说明
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
/**
* 获取到当前Thread的Looper对象
* 然后通知 getLooper 方法, 这个时候可以返回(同步)
*/
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
public Looper getLooper() {
if (!isAlive()) {
return null;
}
// If the thread has been started, wait until the looper has been created.
synchronized (this) {
while (isAlive() && mLooper == null) {
try {
/**
* 等待run方法的Looper对象初始化完成
*/
wait();
} catch (InterruptedException e) {
}
}
}
return mLooper;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
再比如换肤框架 Android-skin-support (opens new window)中 loadSkin 使用了的同步示例:
private final Object mLock = new Object();
public AsyncTask loadSkin(String skinName, SkinLoaderListener listener, int strategy) {
return new SkinLoadTask(listener, mStrategyMap.get(strategy)).execute(skinName);
}
private class SkinLoadTask extends AsyncTask<String, Void, String> {
private final SkinLoaderListener mListener;
private final SkinLoaderStrategy mStrategy;
SkinLoadTask(@Nullable SkinLoaderListener listener, @NonNull SkinLoaderStrategy strategy) {
mListener = listener;
mStrategy = strategy;
}
protected void onPreExecute() {
if (mListener != null) {
mListener.onStart();
}
}
@Override
protected String doInBackground(String... params) {
synchronized (mLock) {
while (mLoading) {
try {
mLock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
mLoading = true;
}
try {
if (params.length == 1) {
if (TextUtils.isEmpty(params[0])) {
SkinCompatResources.getInstance().reset();
return params[0];
}
if (!TextUtils.isEmpty(
mStrategy.loadSkinInBackground(mAppContext, params[0]))) {
return params[0];
}
}
} catch (Exception e) {
e.printStackTrace();
}
SkinCompatResources.getInstance().reset();
return null;
}
protected void onPostExecute(String skinName) {
SkinLog.e("skinName = " + skinName);
synchronized (mLock) {
// skinName 为""时, 恢复默认皮肤
if (skinName != null) {
SkinPreference.getInstance().setSkinName(skinName).setSkinStrategy(mStrategy.getType()).commitEditor();
notifyUpdateSkin();
if (mListener != null) mListener.onSuccess();
} else {
SkinPreference.getInstance().setSkinName("").setSkinStrategy(SKIN_LOADER_STRATEGY_NONE).commitEditor();
if (mListener != null) mListener.onFailed("皮肤资源获取失败");
}
mLoading = false;
mLock.notifyAll();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
# HandlerThread
HandlerThread thread = newHandlerThread("handler_thread");
thread.start();//必须要调用start方法
final Handlerhandler = newHandler(thread.getLooper()){}
2
3
getLooper(): 返回与该线程相关联的 Looper 对象
# CountDownLatch
CountDownLatch 是一种灵活的闭锁实现, 包含一个计数器, 该计算器初始化为一个正数, 表示需要等待事件的数量。countDown 方法递减计数器, 表示有一个事件发生, 而 await 方法等待计数器到达 0, 表示所有需要等待的事情都已经完成. 在完成一组正在其他线程中执行的操作之前, 它允许一个或多个线程一直等待。link
- 例如我们上例中所有人都到达饭店然后吃饭
- 某个操作需要的资源初始化完毕
- 某个服务依赖的线程全部开启等等...
//构造方法参数指定了计数的次数
public CountDownLatch(int count);
//countDown方法, 当前线程调用此方法, 则计数减一
public void countDown();
//awaint方法, 调用此方法会一直阻塞当前线程, 直到计时器的值为0
public void await() throws InterruptedException
2
3
4
5
6
7
8
# Semaphore
// 允许最多0个线程获取许可
final Semaphore semaphore = new Semaphore(0);
final Boolean[] result = new Boolean[1];
fileDecodingQueue.postRunnable(new Runnable() {
@Override
public void run() {
result[0] = openOpusFile(messageObject.location.path) != 0;
semaphore.release();
}
});
semaphore.acquire();
2
3
4
5
6
7
8
9
10
11
<init>(count): 初始许可个数acquire(): 请求许可, 如果没有许可, 那么 acquire 方法将会一直阻塞直到有许可(或者直到被终端或者操作超时)release(): 释放许可
public class MutexPrint {
private final int PrintCount = 2; //打印机的数量
private final Semaphore semaphore = new Semaphore(PrintCount);
public void print(String str) throws InterruptedException {
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + " enter ...");
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + " 正在打印 ..." + str);
System.out.println(Thread.currentThread().getName() + " out ...");
semaphore.release();
}
public static void main(String[] args) {
final MutexPrint print = new MutexPrint();
for (int i = 0; i < 10; i++) {
new Thread() {
public void run() {
try {
print.print("helloworld");
} catch (InterruptedException e) {
e.printStackTrace();
}
};
}.start();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# ReentrantLock
可重入锁, 互斥锁 (opens new window), 用法参照 LinkedBlockingQueue 源码实现
- 重入性: 指的是同一个线程多次试图获取它所占有的锁, 请求会成功。当释放锁的时候, 直到重入次数清零, 锁才释放完毕
ReentrantLock 将由最近成功获得锁, 并且还没有释放该锁的线程所拥有。如果当前线程已经拥有该锁, 此方法将立即返回。可以使用 isHeldByCurrentThread() 和 getHoldCount() 方法来检查此情况是否发生 此类的构造方法接受一个可选的公平 参数。当设置为 true 时, 在多个线程的争用下, 这些锁倾向于将访问权授予等待时间最长的线程。否则此锁将无法保证任何特定访问顺序。与采用默认设置(使用不公平锁)相比, 使用公平锁的程序在许多线程访问时表现为很低的总体吞吐量(即速度很慢, 常常极其慢), 但是在获得锁和保证锁分配的均衡性时差异较小。不过要注意的是, 公平锁不能保证线程调度的公平性。因此, 使用公平锁的众多线程中的一员可能获得多倍的成功机会, 这种情况发生在其他活动线程没有被处理并且目前并未持有锁时。还要注意的是, 未定时的 tryLock 方法并没有使用公平设置。因为即使其他线程正在等待, 只要该锁是可用的, 此方法就可以获得成功
main apiReentrantLock() // 创建一个自由竞争的可重入锁
ReentrantLock(boolean fair)
lock
unlock
isHeldByCurrentThread
getHoldCount
lockInterruptibly
2
3
4
5
6
7
8
**不同: ** 1.ReentrantLock 功能性方面更全面, 比如时间锁等候, 可中断锁等候, 锁投票等, 因此更有扩展性。在多个条件变量和高度竞争锁的地方, 用 ReentrantLock 更合适, ReentrantLock 还提供了 Condition, 对线程的等待和唤醒等操作更加灵活, 一个 ReentrantLock 可以有多个 Condition 实例, 所以更有扩展性 2.ReentrantLock 必须在 finally 中释放锁, 否则后果很严重, 编码角度来说使用 synchronized 更加简单, 不容易遗漏或者出错 3.ReentrantLock 的性能比 synchronized 会好点 4.ReentrantLock 提供了可轮询的锁请求, 他可以尝试的去取得锁, 如果取得成功则继续处理, 取得不成功, 可以等下次运行的时候处理, 所以不容易产生死锁, 而 synchronized 则一旦进入锁请求要么成功, 要么一直阻塞, 所以更容易产生死锁
- Lock 的某些方法可以决定多长时间内尝试获取锁, 如果获取不到就抛异常, 这样就可以一定程度上减轻死锁的可能性 如果锁被另一个线程占据了, synchronized 只会一直等待, 很容易错序死锁
- synchronized 的话, 锁的范围是整个方法或 synchronized 块部分;而 Lock 因为是方法调用, 可以跨方法, 灵活性更大
- 便于测试, 单元测试时, 可以模拟 Lock, 确定是否获得了锁, 而 synchronized
# other
# 线程池
- Java 并发专题 带返回结果的批量任务执行 CompletionService ExecutorService.invokeAll (opens new window)
- JAVA 线程池的分析和使用-ThreadPoolExecutor (opens new window)
Java 四种线程池的使用
- newCachedThreadPool 创建一个可缓存线程池, 如果线程池长度超过处理需要, 可灵活回收空闲线程, 若无可回收, 则新建线程
- newFixedThreadPool 创建一个定长线程池, 可控制线程最大并发数, 超出的线程会在队列中等待
- newScheduledThreadPool 创建一个定长线程池, 支持定时及周期性任务执行
- newSingleThreadExecutor 创建一个单线程化的线程池, 它只会用唯一的工作线程来执行任务, 保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
# 开启线程
# 并发容器
ConcurrentHashMap
ConcurrentLinkedDeque
LinkedBlockingDeque 并发
CopyOnWriteArrayList
- Queue
- Deque
- BlockingDeque
# CopyOnWrite 容器
应用场景CopyOnWrite 容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候, 不直接往当前容器添加, 而是先将当前容器进行 Copy, 复制出一个新的容器, 然后新的容器里添加元素, 添加完元素之后, 再将原容器的引用指向新的容器。这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读, 而不需要加锁, 因为当前容器不会添加任何元素。所以CopyOnWrite 容器也是一种读写分离的思想, 读和写不同的容器.
CopyOnWrite 并发容器用于读多写少的并发场景。比如白名单, 黑名单, 商品类目的访问和更新场景, 假如我们有一个搜索网站, 用户在这个网站的搜索框中, 输入关键字搜索内容, 但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中, 黑名单每天晚上更新一次。当用户搜索时, 会检查当前关键字在不在黑名单当中, 如果在, 则提示不能搜索